

A Unique Unicode Approach to Large Language Model Output Encoding
Emily Baytalsky, Advaith Gowrishetty, Jacob Katuin



This proposal was originally written in April 2025 for independent research following the 2024 Stanford University Ethics, Technology, and Public Policy for Practitioners Course. We expect this content to remain relevant while acknowledging that developments in technology or regulation could strengthen or detract from the claims made.
Summary
Like human generated content, Large Language Model (LLM) output can only be judged in context. However, the speed, scale, and uncertain sourcing of AI present unique challenges for content consumers. As AI-generated text becomes more widespread, content creators and consumers would benefit from opt-in options for identifying AI-generated text. In this paper, we propose the creation of a dedicated LLM Unicode character set. Complementing probabilistic watermarking techniques, this approach would work with certainty for content generators who do not go out of their way to swap out these characters. It would also make it legally unambiguous when AI origins are hidden, helping leverage existing legal frameworks to prosecute malicious AI collaborators. We outline the technical process by which a unique character set can be implemented once approved by the Unicode Consortium.
Background and Methodology
NIST published Report 100-4: Reducing Risks Posed by Synthetic Content on 11/20/24. Included among the challenges identified for implementing and detecting text-based watermarking techniques are:
In Section 3.1.1.3, “Text watermarks generally cannot be embedded or detected reliably when the text has low entropy, i.e., where there are few possible plausible responses to the prompt or continuations of the text. To take the extreme case, it would be hard to distinguish whether the canonical continuation of “1 + 1 =” was generated by GAI.”
In Section 3.1.2, “Metadata can be associated with text… [But] It is not generally possible to have metadata travel with raw text as the text is copied across documents or applications.”
In Section 3.2, “A complication for all detection methods is that a given piece of content may only be partially synthetic.”
These challenges highlight the underlying fact that the implementation and detection of text-based watermarking is exclusively probabilistic and will occasionally fail even under perfect conditions. As Professor Daniel Kang at The UIUC School of Computing and Data Science asserted in a 6/1/24 public comment on NIST’s draft of Report 100-4, “there is no known defense against malicious adversaries.” We believe this to be true for all combinations of approaches to identify content origin. We also believe working to completely prevent adversarial misconduct is incompatible with real world scenarios.
Nevertheless, there are many valid use cases for identifying AI-generated characters distinct from human-generated ones. It is also useful to separate the act of marking text (akin to using a highlighter on text in a letter) from the act of protecting marked text from tampering (akin to sealing that letter inside an envelope.) The former shows which characters were human or AI; the latter proves that the markup was the case at the time the envelope was sealed.
Encoding characters generated by AI from a unique set would preserve content authenticity across good faith human and LLM collaboration. We suggest an opt-in framework to be applied initially where it is expected to be maximally beneficial for social benefits to be realized. Existing legal frameworks could then be leveraged when negligence or malicious intent is present.
One way to think of this is “track changes” for AI, but encoded on a character-by-character basis that survives copying and pasting across applications, operating systems, and devices. How the encoding is used (or whether it is removed) is up to the user; we are simply suggesting a markup mechanism.
Let us illustrate with a simple example in an academic setting. A high school has a longstanding academic integrity policy with which they prosecute undesired behavior. They’ve recently added AI use terms. However, this update has come under scrutiny when students and parents challenge judgments given the probabilistic and often unsatisfactory evidence that a student dishonestly used an LLM. If this school required the use of unique AI characters instead of regulating AI use in general, the question changes from whether AI was used to whether the student knowingly altered the character types. The former is a nebulous accusation given the omnipresence of AI and the latter is a straightforward fraud charge. This change does not add friction to adversarial misconduct, it simply shifts regulatory enforcement away from novel and insufficient approaches to tried and tested frameworks.
The simplest instantiation of this approach and the method the authors recommend is a unique character set within Unicode, first put forward by Alistair Croll in WIRED in July 2023. He followed up that article with additional detail in Unicode is all you need on his Substack. The culmination of his effort was documented in another Substack post, How to watermark AI. This report documents an investigation that was performed using stakeholder mapping to identify advocacy opportunities. Additionally, the technical process for updating Unicode is identified to show the ease with which this recommendation could be implemented.
Key Findings
Pushback Against Probabilistic Watermarking
In November 2024, David Gilbertson published a Medium article, Why LLM watermarking will never work. At the end of the article, he posed several questions to proponents of watermarking. The distilled primary concerns are:
How can watermarking some LLMs be expected to reduce harm given the presence of malicious users?
Do you propose that LLM providers modify their product in any way?
Where do you draw the line between AI and human text?
While it’s clear that Gilbertson is only considering probabilistic watermarking solutions with these questions, responses framed against this proposal add value to the conversation. In response to his questions, respectively:
Q: How can watermarking some LLMs be expected to reduce harm given the presence of malicious users?
A: Both humans and LLMs are capable of generating harmful content and there is no way to prevent that. The goal of this proposal is to unlock existing legal frameworks to prosecute malicious AI collaborators and leverage social friction to combat the increased scale of AI tools.
Q: Do you propose that LLM providers modify their product in any way?
A: No. Existing LLM models would not have to be modified, just appended to. Modifying variables such as temperature or changing LLM architecture affects generation, which our proposal does not suggest. We propose only an additional toggle-able step before outputs are presented to users. This means no functionality will have to be changed. Additionally, this proposal does not differentiate between open source and closed models.
Q: Where do you draw the line between AI and human text?
A: AI text is that which is directly output by an LLM and human text is that which is directly output by a human brain. This proposal allows humans and LLMs to collaborate with no content pedigree being lost in the process. To accommodate common use cases like summarization or translation, further unique Unicode character sets can be established as deemed appropriate. E.g. a human generated paragraph that is merely translated by an LLM could be assigned an “LLM translation” character set rather than an “LLM generation” character set.
Process to Update Unicode
Our goal is to add a Unicode character set specifically for AI generated characters. This parallel set will be encoded differently such that a “highlighter” can be activated to identify them. Unicode is beneath the font layer, so fonts are unaffected by this change. There is precedent showing this is possible, as duplicate unicode characters already exist for roman numerals and greek letters.
There are currently around 155k characters encoded in the Unicode standard, and the current standard supports around 1.1 million characters. This means it is feasible to add an AI generated character set within the limits of the current standard.
The Unicode Symposium currently handles changes to Unicode. Proposals are submitted here, which the symposium then reviews, a process that can take anywhere from months to years. The current pipeline to add new characters to Unicode doesn’t account for the scale of this project, and thus might not be applicable to our undertaking.
It is also noteworthy that the three stakeholder groups required to implement this proposal—the LLM providers, the operating system owners, and the members of the Unicode Consortium—overlap considerably: Apple, Microsoft, and Google are leading participants in all three bodies.
Societal and Economic Value Proposition
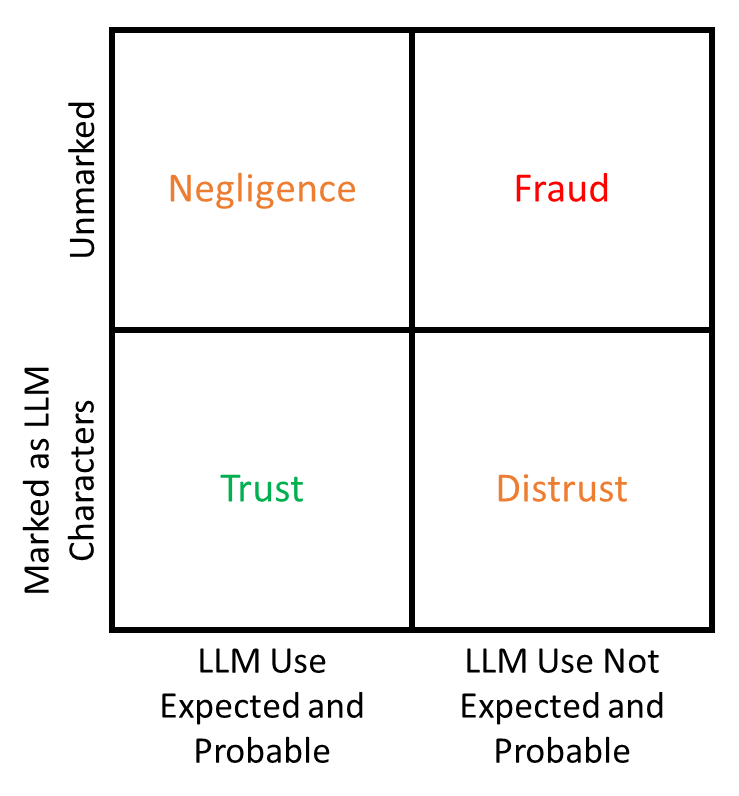
The potential for authentic humans and LLMs to inadvertently create the exact same content is addressed by the deterministic watermark (LLM Unicode characters) and the potential for authentic humans and LLMs to inadvertently create similar content is addressed by any given ecosystem’s probabilistic watermark. As a thought experiment, take this 2x2 matrix of logical responses to counterparty behavior after the adoption of this proposal. The recipient can readily make a directional assessment that is higher resolution than the conclusion that can be drawn without the presence of deterministic information. A main benefit of this assessment is that the conclusions it allows align with current legal frameworks. At scale, including deterministic identification of AI generated content has the potential to allow society to settle on a more transparent/less obfuscated game-theoretic information landscape as compared to a future with only probabilistic detection methods.
Stakeholders and Their Incentives
To identify a route for advocacy, the following stakeholder categories were considered: LLM development companies, governments, content creators, and content consumers. While there is a spectrum of opinions across individual stakeholders, it seems reasonable to assume the average position of the categories falls loosely along this influence vs interest spectrum.
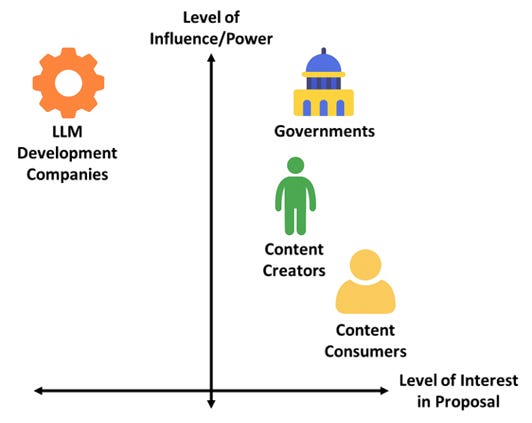
We expect LLM development companies to have strong negative interest in implementing this proposal due to studies like those conducted by OpenAI that indicate that users would use LLMs nearly 30% less if they were watermarked. Additionally, making outputs distinguishable may hamper adoption in certain contexts. These companies hold the ultimate ability to implement this proposal. Governments are likely to recognize the economic, societal, and legal benefit of this proposal and additionally have the capability to enforce such a solution through both direct and indirect means. Content creators are expected to have moderate individual influence and moderate interest in this proposal as they are humans who value their authenticity in society amidst a flood of LLM content. Content consumers have lower power and higher interest than their creator counterparts due to directly benefiting from authenticity pedigree by observation. Consumers have another benefit via not being accused of being inauthentic, but this is weighted lower due to being a benefit of omission.
Opt-In Value Proposition
The value proposition from our proposal lies (or begins with) an opt-in scenario for individual users. For what could be an initial test, consider a browser plug-in or LLM wrapper which encodes all LLM output into the Unicode set. For a content creator, the benefit of ‘toggling on’ lies both in a virtue signal and a way to distinguish one’s material as authentically their own. In the current economy of online authors, one could garner more trust or support if users believe they can discern that the content is human generated. In fact, even if the author is aided by LLMs, they would still benefit from our proposal, as it would be traceable which parts of their article are from an LLM. An organization that wants to claim LLM transparency, or “no-GPT”, could use this approach to prove their integrity to their customers.
While optimistic, this phenomenon isn’t new among image and long-form video content platforms like Instagram and YouTube, respectively. Makeup content creators whose platform rests on authenticity will often disclose when a product they use was sponsored or sent by a company, even if they are not always legally obligated to do so. Fashion content creators often disclose when they are using filters, showing ‘before and afters’ in an attempt to connect with users, build their base, and potentially alleviate the social ills of false standards and mental health issues spurred by the use of airbrushing, filtering, and editing.
The protocol could expand beyond its original use case to contain social signals and generational alignment; for example, hashtags are used across the internet even where they don’t serve as a categorization tool.
Governments could also influence the behavior of LLM providers by including the markup functionality in their RFPs and procurement guidelines, offering a financial incentive.
Recommendations
Unique Unicode Character Sets
Implementing one or multiple Unicode character sets dedicated to LLMs alongside individual LLM developer’s probabilistic watermarking techniques is expected to offer substantial benefits compared to just the latter. Due to the abundance of LLM-generated information that is already promulgated across the internet, benign or harmful, identifying the authenticity of human-generated content is an immediate challenge.
We acknowledge that not all LLM use is created equally. People should have the opportunity to use LLM outputs with nuance that differentiates between content generation and content summarization or translation. This can be accomplished with a slight expansion to this proposal and is flexible to accommodate future use cases.
Stakeholder Engagement
The stakeholders we believe to be most receptive to implementing a user opt-in unique Unicode character set and would carry the maximum influence are online content platforms specific to authors, such as Substack and Medium. As is observed on other platforms, particularly image hosting platforms like Instagram, AI content is a sufficient challenge that the platforms are seeking users’ help to tag it. It is unknown how pervasive this problem is on text-based platforms, but it seems reasonable to assume that it’s a measurable phenomenon. Whether this phenomenon is simply taking up server space or is actively degrading the quality of prominent authors, there is value in easily identifying LLM-generated content for the associated platform.
The product teams at Substack and Medium may be receptive to a discussion about the impact of this feature as an opt-in toggle for their users. In the best case scenario, they could represent their organizations and serve as advocacy champions with the Unicode Consortium for a dedicated LLM character set.
The Unicode Path Forward
Updating Unicode to allow for one or more parallel character sets comes with its own set of considerations. LLMs can currently generate any Unicode characters, which means all Unicode characters need to have an AI generated equivalent in the long run. It’s possible to start with English letters, punctuation, and numbers, but eventually this means at least double the total number of Unicode characters.
Updating current LLMs to generate content in this new character set is expected to be relatively straightforward once the character set exists. The optional toggle to use the new character set would switch on an additional character conversion step after LLM output generation before outputting it to the user. This would make sure any output is in the AI generated character set. The implementation details would be up to the LLM developers, but shouldn’t be technically challenging. An additional step necessary upon execution would be making sure both character sets are properly converted when re-input into LLMs.
Adding a new character set would not directly impact fonts, which alleviates a large concern for adoption. Not all fonts support all Unicode characters, but it is possible to map multiple Unicode characters to the same glyph in a font (such as with roman numerals and mathematical symbols), meaning the new character set can simply map to the font representation of the old character set. Commonly used operating systems and browsers mostly support new unicode characters, with the limiting factor usually being fonts, and thus the problem of display should be naturally resolved as operating systems map the new characters to their fonts.
While this is a substantial change, the primary blocker is adding a large new Unicode character set relative to the total space available - which means the support of the Consortium is necessary. The cooperation of companies like Google, Microsoft, Apple, and Meta who are part of the symposium, and also leaders in LLM usage, is essential.
Conclusion
LLM output is, by design, largely indistinguishable from human generated content given their training corpuses. All current AI text detection methods are probabilistic, ranging in complexity from low-end tools like Winston AI and GPT Zero, to more advanced steganographic systems such as Google DeepMind’s SynthID. The use of these detection methods results in haphazard enforcement of AI use guidelines. There are benefits to provenance tracking techniques that allow for the deterministic identification of AI generated content, both natural language and software code. On-device LLM character encoding with supplemental Unicode character sets offers a straightforward approach to augment AI use guidelines by holding LLM collaborators accountable with existing legal frameworks. An opt-in trial of this concept could be applied to text-based content platforms, such as Substack and Medium, where both contributors and consumers would benefit from the preservation of authenticity.
Acknowledgements
Thanks to Alistair Croll, Mauricio Baker, and Nicole Timofeevski for bringing their expertise to review and provide feedback on this proposal.
 | A guest post by
|
 | A guest post by
|